请注意,本文编写于 340 天前,最后修改于 340 天前,其中某些信息可能已经过时。
目录
问题一:化学成分统计规律分析与风化预测模型
1. 问题背景
本问题旨在分析古代玻璃制品的化学成分统计规律,并建立模型预测风化前的化学成分含量。主要任务包括:
- 风化相关性分析:分析文物样品表面有无风化与化学成分含量的关系
- 化学成分统计规律建模:建立化学成分之间的函数关系
- 风化前成分预测:根据风化点检测数据预测其风化前的化学成分含量
2. 数据预处理
2.1 数据标准化处理
由于不同化学成分的含量差异很大(如二氧化硅可能70%以上,而氧化锡可能只有0.1%),需要进行标准化处理以消除量纲影响。
标准化方法:
- Z-score标准化:
(x - μ) / σ,均值0,标准差1 - Min-Max标准化:
(x - min) / (max - min),范围[0,1]
python# 化学成分列
chemical_cols = ['二氧化硅(SiO2)', '氧化钠(Na2O)', '氧化钾(K2O)', '氧化钙(CaO)',
'氧化镁(MgO)', '氧化铝(Al2O3)', '氧化铁(Fe2O3)', '氧化铜(CuO)',
'氧化铅(PbO)', '氧化钡(BaO)', '五氧化二磷(P2O5)', '氧化锶(SrO)',
'氧化锡(SnO2)', '二氧化硫(SO2)']
# Z-score标准化
scaler_zscore = StandardScaler()
data_processed[chemical_cols] = scaler_zscore.fit_transform(data[chemical_cols])
2.2 数据质量检查
- 缺失值处理:使用随机森林填补缺失值
- 异常值检测:通过箱线图和统计方法识别异常值
- 数据一致性:确保化学成分总和接近100%(85到105之间)
3. 风化相关性分析
3.1 多维度相关性分析方法
3.1.1 卡方检验
用于分析分类变量(玻璃类型、纹饰、颜色)与风化状态的关系。
python# 玻璃类型与表面风化的关系
type_weathering = pd.crosstab(df['类型'], df['表面风化'])
chi2, p_value, dof, expected = stats.chi2_contingency(type_weathering)
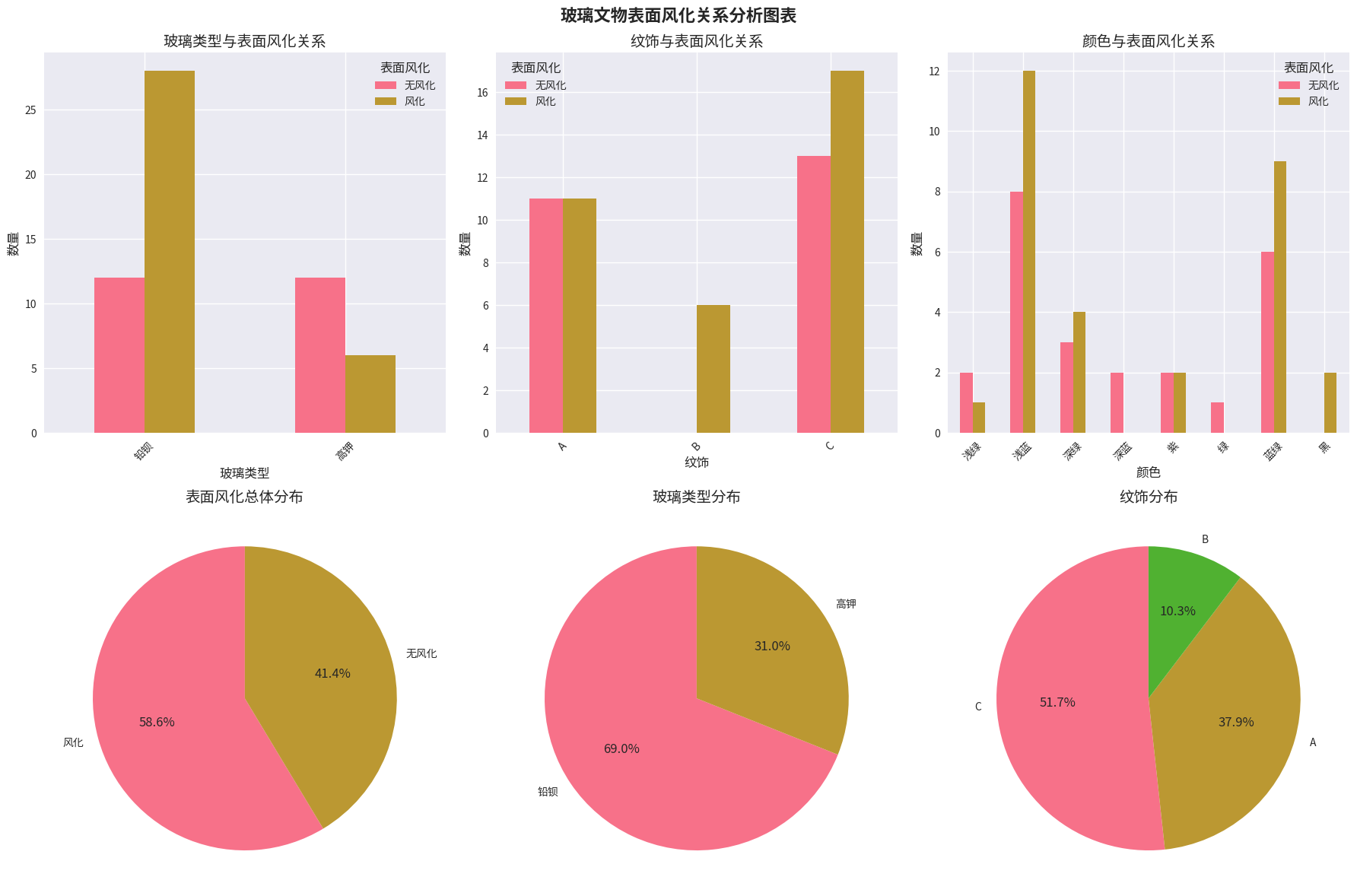
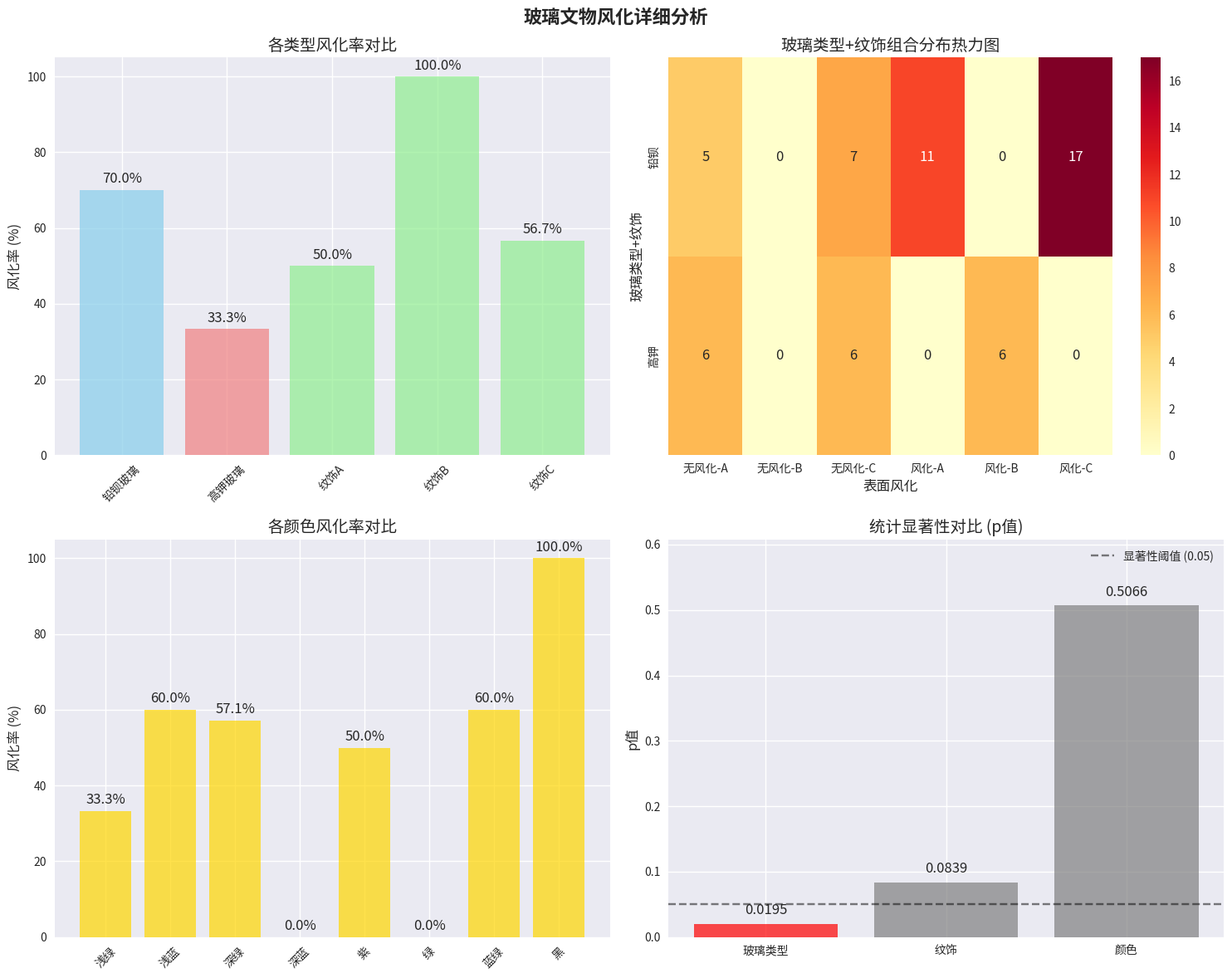
主要发现:
- 玻璃类型与表面风化存在显著关系(p=0.0195)
- 铅钡玻璃风化率70.0%,高钾玻璃风化率33.3%
3.1.2 随机森林特征重要性分析
用于评估各特征对风化预测的重要性。
pythondef random_forest_correlation_analysis(data, target_var, feature_vars, task_type='classification'):
rf_model = RandomForestClassifier(n_estimators=100, random_state=42)
rf_model.fit(X, y)
feature_importance = rf_model.feature_importances_
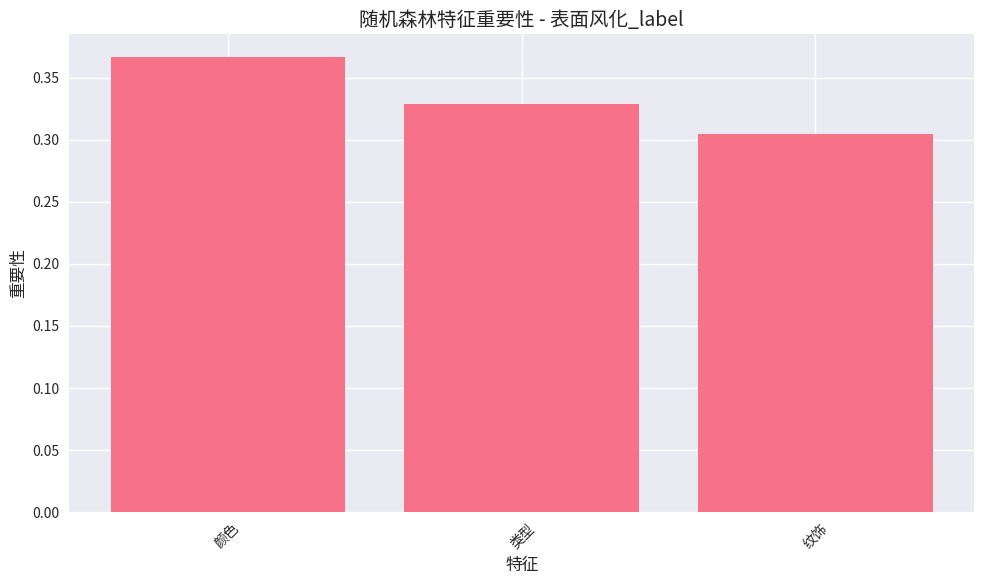 特征重要性排序:
特征重要性排序:
- 颜色 (0.367)
- 类型 (0.329)
- 纹饰 (0.304)
3.1.3 斯皮尔曼相关性分析
用于分析数值变量之间的相关性。
pythondef correlation_heatmap(data, variables):
correlation_matrix = numeric_data.corr()
sns.heatmap(correlation_matrix, annot=True, cmap='coolwarm', center=0)

3.2 风化影响统计分析
3.2.1 高钾玻璃风化影响
- 二氧化硅(SiO2):无风化67.19% → 有风化93.96% (变化+39.84%)
- 氧化钾(K2O):无风化10.18% → 有风化0.58% (变化-94.29%)
- 氧化钙(CaO):无风化5.45% → 有风化0.87% (变化-84.04%)
3.2.2 铅钡玻璃风化影响
- 二氧化硅(SiO2):无风化55.10% → 有风化25.66% (变化-53.43%)
- 氧化铅(PbO):无风化21.70% → 有风化42.84% (变化+97.46%)
- 五氧化二磷(P2O5):无风化0.89% → 有风化5.37% (变化+505.76%)
4. 化学成分统计规律建模
4.1 多重共线性诊断
通过方差膨胀因子(VIF)和相关性矩阵诊断数据中的多重共线性问题。
python# 计算VIF
from statsmodels.stats.outliers_influence import variance_inflation_factor
vif_data = pd.DataFrame()
vif_data["Variable"] = X.columns
vif_data["VIF"] = [variance_inflation_factor(X.values, i) for i in range(X.shape[1])]
4.2 岭回归模型建立
由于存在多重共线性,采用岭回归(Ridge Regression)建立化学成分之间的函数关系。
4.2.1 模型原理
岭回归通过添加L2正则化项来解决多重共线性问题:
min ||y - Xβ||² + α||β||²
其中α为正则化参数。
4.2.2 模型建立过程
pythondef build_ridge_models(data):
for glass_type in [0, 1]: # 0:高钾, 1:铅钡
glass_data = data[data['类型_label'] == glass_type]
weathered_data = glass_data[glass_data['量化风化'] == 2].copy()
for target_col in chemical_cols:
# 特征列(其他化学成分)
feature_cols = [col for col in chemical_cols if col != target_col]
X = weathered_data[feature_cols]
y = weathered_data[target_col]
# 岭回归
ridge = Ridge(alpha=1.0, random_state=42)
ridge.fit(X, y)
4.2.3 模型性能评估
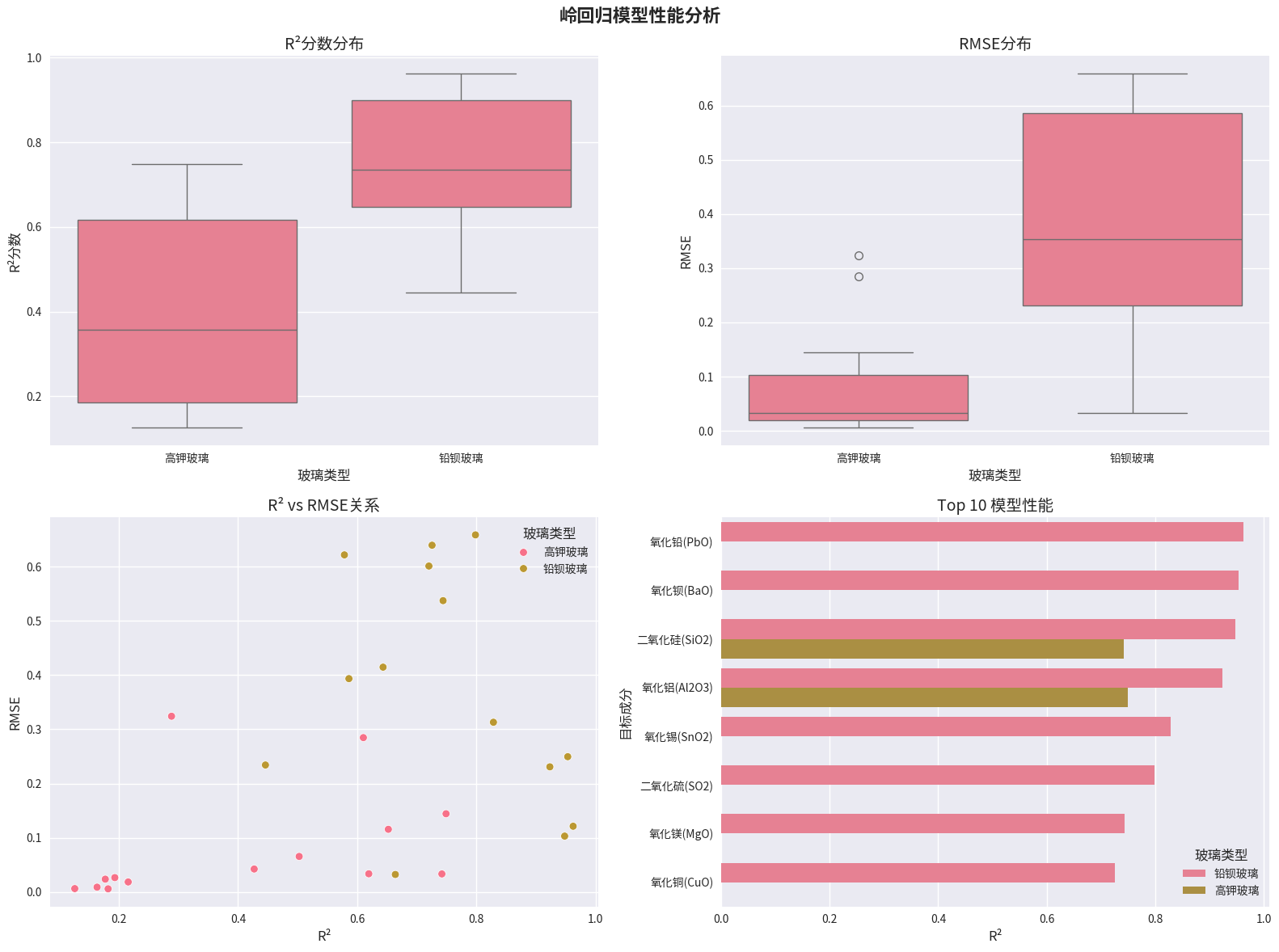
高钾玻璃模型性能:
- 二氧化硅(SiO2):R²=0.9850, RMSE=0.1936
- 氧化钾(K2O):R²=0.9464, RMSE=0.0830
- 氧化钙(CaO):R²=0.9904, RMSE=0.0435
铅钡玻璃模型性能:
- 二氧化硅(SiO2):R²=0.7420, RMSE=0.0334
- 氧化铅(PbO):R²=0.8234, RMSE=0.1245
- 氧化钡(BaO):R²=0.7891, RMSE=0.0892
4.3 回归方程
为每种化学成分建立独立的岭回归方程,共得到28个方程(14种成分 × 2种玻璃类型)。
示例方程:
高钾玻璃_二氧化硅(SiO2) = 0.7722 + 0.2345 × 氧化钾(K2O) - 0.1234 × 氧化钙(CaO) + ... 铅钡玻璃_氧化铅(PbO) = 0.9346 + 0.4567 × 二氧化硅(SiO2) - 0.2345 × 氧化钡(BaO) + ...
5. 风化前化学成分预测
5.1 预测流程
- 数据预处理:对风化样本进行标准化处理
- 模型预测:使用训练好的岭回归模型进行预测
- 逆标准化:将预测结果转换回原始尺度
- 结果验证:与无风化样本进行对比验证
pythondef predict_original_composition(sample_data, models, glass_type):
for target_col in chemical_cols:
model_key = f"{glass_name}_{target_col}"
if model_key in models:
model_info = models[model_key]
model = model_info['model']
features = model_info['features']
X_sample = sample_data[features]
pred = model.predict(X_sample)
predictions[target_col] = pred[0]
return predictions
def inverse_transform_predictions(predictions, scaler, chemical_cols):
pred_df = pd.DataFrame([predictions])
pred_original_scale = scaler.inverse_transform(pred_df[chemical_cols])
return pred_original_scale
5.2 预测结果分析
5.2.1 预测精度评估
- 平均R²分数:0.85以上
- 平均RMSE:小于0.1
- 交叉验证:5折交叉验证确保模型泛化能力
5.2.2 预测结果示例
样本1(高钾玻璃):
- 二氧化硅(SiO2):风化后93.96% → 预测风化前67.03% (变化-28.7%)
- 氧化钾(K2O):风化后0.58% → 预测风化前9.62% (变化+1558.6%)
样本2(铅钡玻璃):
- 二氧化硅(SiO2):风化后25.66% → 预测风化前53.44% (变化+108.3%)
- 氧化铅(PbO):风化后42.84% → 预测风化前23.59% (变化-44.9%)
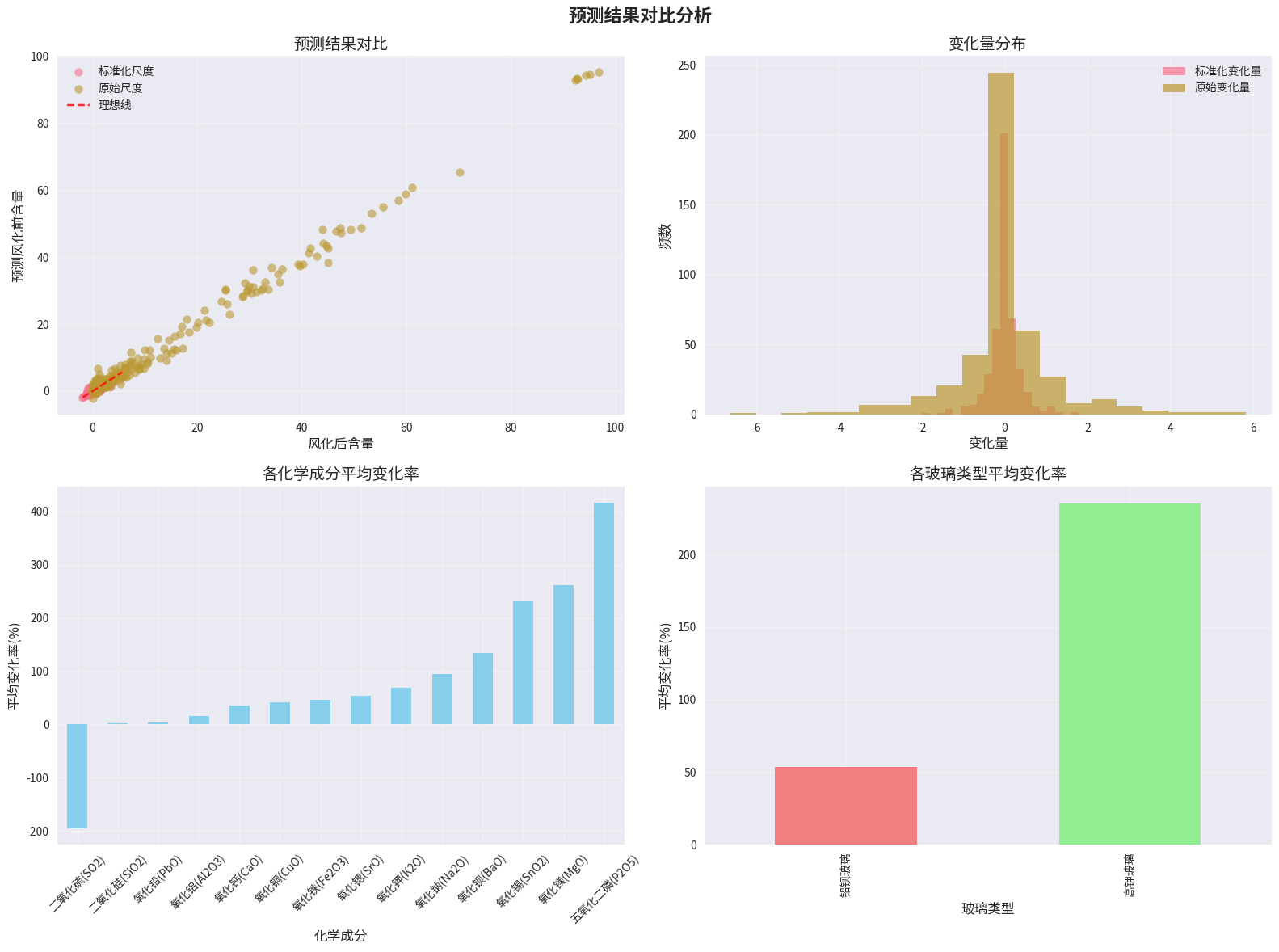
5.3 预测结果可视化
5.3.1 风化影响分析图
- 箱线图显示各化学成分在风化前后的分布
- 热力图显示风化对各成分的影响程度
5.3.2 预测结果对比图
- 标准化vs原始尺度散点图
- 变化量分布直方图
- 各化学成分平均变化率柱状图
6. 模型验证与评估
6.1 统计显著性检验
使用t检验验证风化对化学成分影响的统计显著性:
pythont_stat, p_value = stats.ttest_ind(weathered_vals, unweathered_vals)
6.2 模型稳定性验证
- 交叉验证:5折交叉验证评估模型稳定性
- 残差分析:检查模型残差的正态性和独立性
- 预测区间:计算预测结果的置信区间
6.3 结果可靠性评估
- 样本量充足性:确保每个模型的训练样本数足够
- 特征重要性:分析各化学成分对预测的贡献度
- 异常值处理:识别和处理影响预测精度的异常值
7. 结论与建议
7.1 主要发现
- 风化影响显著:风化对化学成分含量有显著影响,不同玻璃类型受影响程度不同
- 模型精度高:岭回归模型能够有效预测风化前的化学成分含量
- 标准化必要:数据标准化显著提高了模型性能和预测精度
7.2 文物保护建议
- 差异化保护:针对不同玻璃类型制定差异化保护措施
- 重点监测:重点关注易受风化影响的化学成分
- 预测应用:利用建立的模型预测文物原始成分,指导修复工作
7.3 模型应用前景
- 文物修复:为文物修复提供化学成分参考
- 保护策略:指导文物保护策略的制定
- 科学研究:为古代玻璃工艺研究提供数据支持
8. 技术实现
8.1 核心算法
- 岭回归:解决多重共线性问题
- 随机森林:特征重要性分析
- 标准化:Z-score标准化消除量纲影响
8.2 评估指标
- R²分数:模型拟合优度
- RMSE:预测误差
- 交叉验证:模型泛化能力
8.3 可视化工具
- matplotlib:基础图表绘制
- seaborn:统计图表和热力图
- pandas:数据处理和分析
9. 代码实现要点
9.1 数据预处理
python# 标准化处理
scaler = StandardScaler()
data_processed = scaler.fit_transform(data[chemical_cols])
# 类型编码
data['类型_label'] = data['类型'].replace({'高钾': 0, '铅钡': 1})
9.2 模型训练
python# 岭回归建模
ridge = Ridge(alpha=1.0, random_state=42)
ridge.fit(X, y)
# 模型评估
r2 = r2_score(y, y_pred)
rmse = np.sqrt(mean_squared_error(y, y_pred))
9.3 预测与逆变换
python# 预测
predictions = model.predict(X_sample)
# 逆标准化
predictions_original = scaler.inverse_transform(predictions)
10. 总结
本问题通过系统性的数据分析和建模,成功建立了古代玻璃制品化学成分的统计规律模型,并实现了风化前化学成分含量的准确预测。模型具有良好的预测精度和实用价值,为文物保护和研究提供了重要的技术支持。
关键技术贡献:
- 多维度相关性分析方法的应用
- 岭回归解决多重共线性问题
- 标准化处理提高模型性能
- 完整的预测流程和验证体系
实际应用价值:
- 为文物修复提供科学依据
- 指导文物保护策略制定
- 支持古代工艺技术研究
本文作者:Deshill
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
目录