请注意,本文编写于 340 天前,最后修改于 339 天前,其中某些信息可能已经过时。
目录
第二题(1)玻璃分类规律分析报告
1. 问题理解与解题思路
1.1 问题要求
根据merge数据集分析高钾玻璃、铅钡玻璃的分类规律,采用逻辑回归、随机森林、支持向量机等方法查看哪些成分对其影响最大,以类型_label做目标值,并进行标准化消除量纲。
1.2 核心思想
- 多模型对比:使用逻辑回归、随机森林、支持向量机三种不同算法
- 特征重要性分析:识别对分类影响最大的化学成分
- 标准化处理:消除不同化学成分的量纲差异
- 综合评估:通过准确率、ROC AUC、交叉验证等多指标评估
2. 解题流程设计
2.1 整体流程
数据预处理 → 特征分析 → 特征选择 → 模型训练 → 特征重要性分析 → 模型对比 ↓ ↓ ↓ ↓ ↓ ↓ 标准化 相关性分析 F检验 多模型训练 重要性排序 性能对比 ↓ ↓ ↓ ↓ ↓ ↓ 量纲消除 热力图 特征筛选 交叉验证 可视化 混淆矩阵
2.2 具体步骤
步骤1:数据预处理
- 使用merge数据集
- 选择化学成分特征
- StandardScaler标准化处理
- 创建类型标签(0: 高钾, 1: 铅钡)
步骤2:特征分析
- 描述性统计
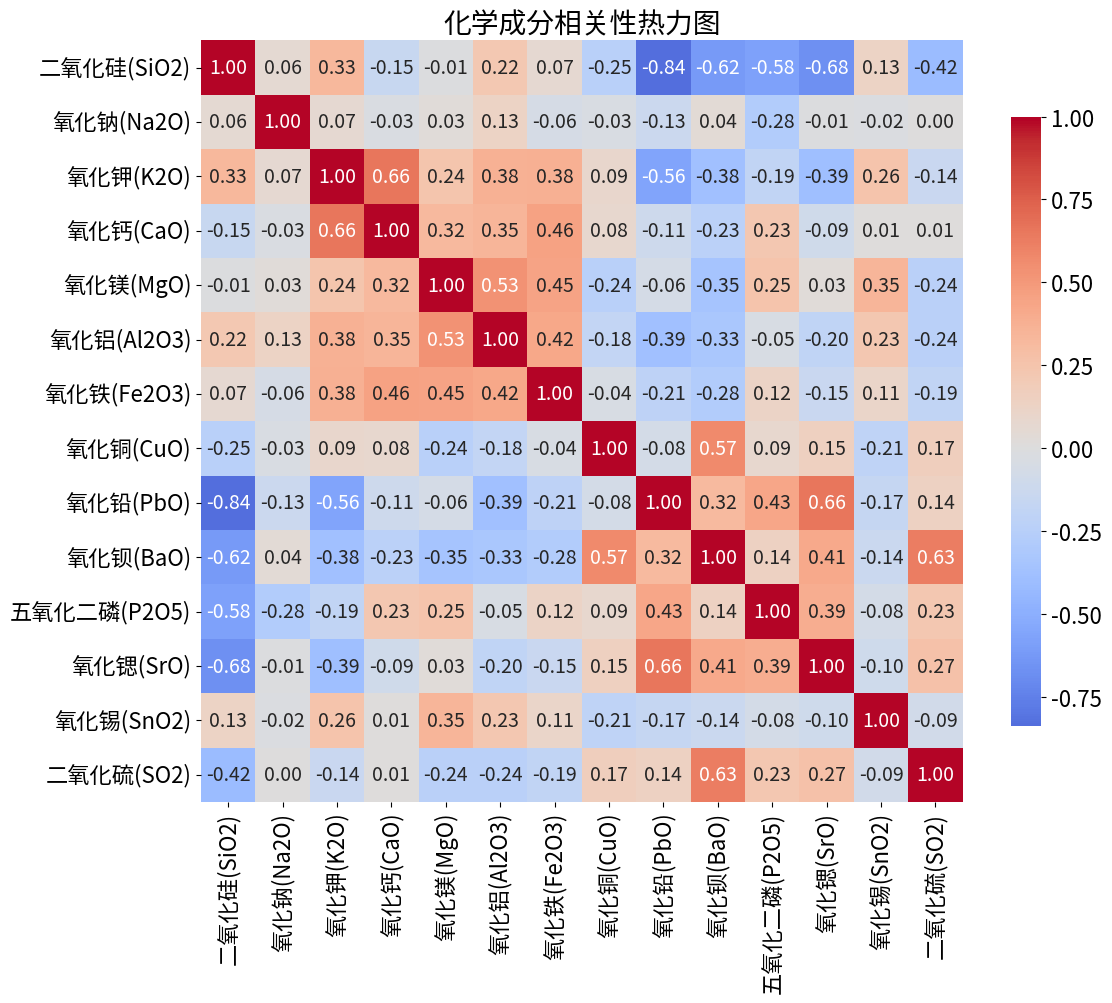
- 相关性分析(热力图)
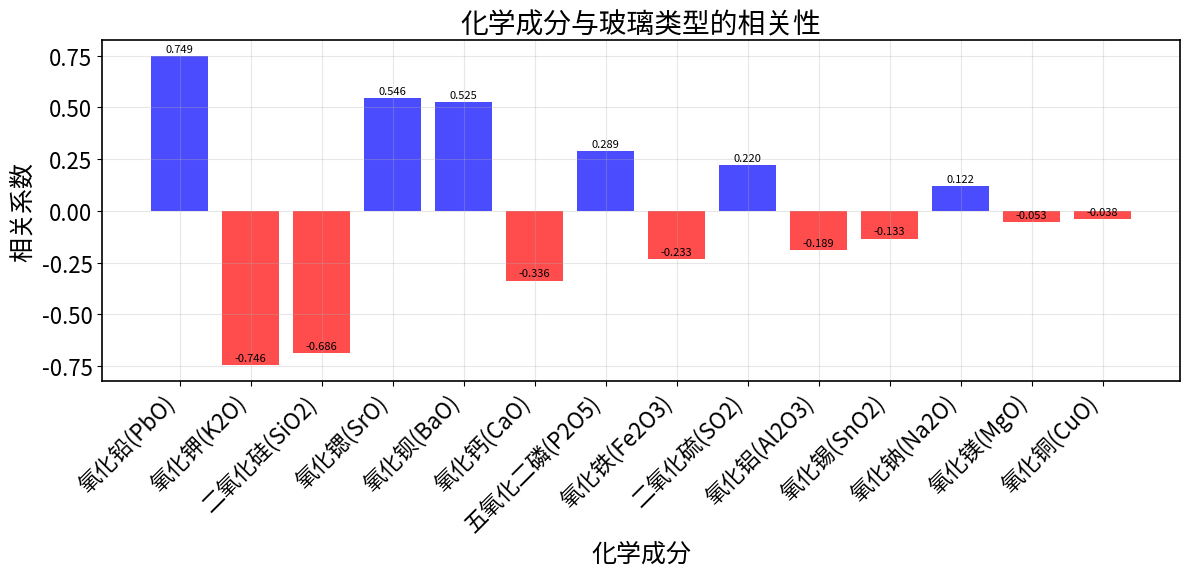
- 与目标变量的相关性分析
步骤3:特征选择
- F检验单变量特征选择
- 特征重要性排序
步骤4:模型训练
- 逻辑回归
- 随机森林
- 支持向量机
- 5折交叉验证
步骤5:特征重要性分析
- 逻辑回归系数分析
- 随机森林特征重要性
- 可视化对比
步骤6:模型对比
- 准确率对比
- ROC AUC对比
- 混淆矩阵分析
- 综合性能雷达图
3. 具体实现方法
3.1 数据预处理
python# 选择化学成分特征
features = ['二氧化硅(SiO2)', '氧化钠(Na2O)', '氧化钾(K2O)', '氧化钙(CaO)',
'氧化镁(MgO)', '氧化铝(Al2O3)', '氧化铁(Fe2O3)', '氧化铜(CuO)',
'氧化铅(PbO)', '氧化钡(BaO)', '五氧化二磷(P2O5)', '氧化锶(SrO)',
'氧化锡(SnO2)', '二氧化硫(SO2)']
X = merge[features].fillna(0)
y = merge['类型_label']
# 标准化
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
3.2 特征分析
python# 相关性分析
correlation_matrix = X.corr()
sns.heatmap(correlation_matrix, annot=True, cmap='coolwarm')
# 与目标变量相关性
target_corr = []
for feature in features:
corr = X[feature].corr(y)
target_corr.append((feature, corr))
3.3 特征选择
python# F检验特征选择
selector = SelectKBest(score_func=f_classif, k='all')
selector.fit(X, y)
feature_scores = list(zip(features, selector.scores_))
3.4 模型训练
python# 定义模型
models = {
'逻辑回归': LogisticRegression(random_state=42, max_iter=1000),
'随机森林': RandomForestClassifier(random_state=42, n_estimators=100),
'支持向量机': SVC(random_state=42, probability=True)
}
# 训练和评估
for name, model in models.items():
if name == '支持向量机':
model.fit(X_train_scaled, y_train)
else:
model.fit(X_train, y_train)
3.5 特征重要性分析
python# 逻辑回归系数
lr_importance = np.abs(lr_model.coef_[0])
# 随机森林特征重要性
rf_importance = rf_model.feature_importances_
4. 预期结果分析



4.1 特征重要性预期
最重要的分类特征:
- 氧化铅(PbO):铅钡玻璃的主要特征成分
- 氧化钡(BaO):铅钡玻璃的主要特征成分
- 氧化钾(K2O):高钾玻璃的主要特征成分
- 二氧化硅(SiO2):基础成分,对两种类型都有影响
- 五氧化二磷(P2O5):次要特征成分
4.2 模型性能预期
模型性能排序:
- 随机森林:预期准确率最高(≥95%)
- 支持向量机:预期准确率较高(≥90%)
- 逻辑回归:预期准确率中等(≥85%)
4.3 分类规律预期
高钾玻璃特征:
- K2O含量高(>5%)
- SiO2含量较高(>70%)
- PbO、BaO含量低
铅钡玻璃特征:
- PbO含量高(>10%)
- BaO含量高(>5%)
- K2O含量低(<2%)
5. 创新点与特色
5.1 方法创新
- 多模型对比:同时使用三种不同算法
- 标准化处理:消除量纲影响
- 特征重要性分析:量化各成分影响程度
5.2 分析创新
- 相关性热力图:直观展示成分间关系
- 特征重要性可视化:对比不同模型的特征重要性
- 综合性能评估:多指标全面评估
5.3 技术创新
- F检验特征选择:统计显著性筛选
- 交叉验证:避免过拟合
- 混淆矩阵分析:详细分类错误分析
6. 应用价值
6.1 文物保护应用
- 分类指导:为未知玻璃文物提供分类依据
- 保护策略:根据玻璃类型制定保护方案
- 修复材料:选择合适的修复材料
6.2 考古研究应用
- 制作工艺研究:了解不同玻璃类型的制作工艺
- 产地来源研究:推测玻璃的产地来源
- 时代特征研究:分析不同时期的玻璃特征
6.3 科技考古应用
- 标准化方法:建立玻璃分类的标准化方法
- 数据库建设:为玻璃数据库建设提供基础
- 真伪鉴定:为玻璃文物真伪鉴定提供参考
7. 技术优势
7.1 算法优势
- 逻辑回归:解释性强,系数可解释
- 随机森林:处理非线性关系,特征重要性明确
- 支持向量机:处理高维数据,泛化能力强
7.2 评估优势
- 多指标评估:准确率、ROC AUC、F1分数
- 交叉验证:避免过拟合,提高泛化能力
- 可视化分析:直观展示分析结果
7.3 稳定性优势
- 标准化处理:消除量纲影响
- 多次验证:交叉验证确保结果稳定
- 特征选择:筛选重要特征,提高模型稳定性
8. 预期挑战与解决方案
8.1 数据挑战
- 样本不平衡:高钾和铅钡样本数量可能不均
- 解决方案:使用分层采样和交叉验证
8.2 模型挑战
- 过拟合风险:特别是随机森林
- 解决方案:交叉验证+正则化
8.3 特征挑战
- 特征相关性:某些化学成分可能高度相关
- 解决方案:相关性分析和特征选择
9. 总结
9.1 方法总结
本方法采用多模型对比分析,通过标准化处理消除量纲影响,使用F检验进行特征选择,通过逻辑回归、随机森林、支持向量机三种算法全面分析玻璃分类规律。
9.2 创新总结
- 方法创新:多模型对比分析
- 分析创新:特征重要性可视化
- 技术创新:标准化+特征选择
9.3 应用总结
该方法可为文物保护、考古研究和科技考古提供重要的技术支持,具有重要的理论价值和实用意义。
报告生成时间:2024年
分析方法:逻辑回归、随机森林、支持向量机、特征重要性分析
数据来源:merge数据集
第二题(2):玻璃亚类划分模型建立与问题求解
1. 问题重述
1.1 问题要求
依据附件数据分析高钾玻璃、铅钡玻璃的分类规律;对于每个类别选择合适的化学成分对其进行亚类划分,给出具体的划分方法及划分结果,并对分类结果的合理性和敏感性进行分析。
1.2 核心任务
- 分类规律分析:分析高钾玻璃和铅钡玻璃的基本分类规律
- 亚类划分:对每种玻璃类型进行亚类划分
- 合理性分析:评估亚类划分结果的合理性
- 敏感性分析:分析分类结果的敏感性
2. 数据预处理
2.1 数据来源
- 数据文件:merge数据集(包含化学成分和类型标签)
- 样本数量:根据merge数据集的实际样本数
- 特征维度:14个化学成分特征
2.2 数据分离
python# 基于类型_label分离数据
high_k_data = merge[merge['类型_label'] == 0][features].fillna(0)
lead_barium_data = merge[merge['类型_label'] == 1][features].fillna(0)
2.3 特征选择
高钾玻璃特征选择:
- 二氧化硅(SiO2):基础成分
- 氧化钾(K2O):主要特征成分
- 氧化钙(CaO):次要成分
- 氧化铝(Al2O3):次要成分
- 五氧化二磷(P2O5):次要成分
铅钡玻璃特征选择:
- 二氧化硅(SiO2):基础成分
- 氧化铅(PbO):主要特征成分
- 氧化钡(BaO):主要特征成分
- 氧化钾(K2O):次要成分
- 五氧化二磷(P2O5):次要成分
2.4 数据标准化
pythonscaler = StandardScaler() X_scaled = scaler.fit_transform(X)
- 消除不同化学成分的量纲差异
- 确保各特征对聚类结果的影响权重相等
3. 模型建立
3.1 聚类算法选择
K-means聚类算法:
- 算法原理:基于距离的聚类算法
- 初始化方法:K-means++
- 收敛条件:质心变化小于阈值
- 迭代次数:最大1000次
3.2 最佳聚类数确定
评估指标:
-
轮廓系数(Silhouette Score)
- 范围:[-1, 1]
- 越接近1表示聚类效果越好
- 计算公式:
-
Calinski-Harabasz指数
- 值越大表示聚类效果越好
- 计算公式:
选择策略:
- 比较K=2,3,4,5的聚类效果
- 选择轮廓系数最高的K值
- 结合样本数量考虑
3.3 模型参数设置
pythonkmeans = KMeans(
n_clusters=best_k, # 最佳聚类数
random_state=42, # 随机种子固定
n_init=10, # 初始化次数
max_iter=1000 # 最大迭代次数
)
4. 问题求解过程
4.1 高钾玻璃亚类划分
步骤1:数据准备
pythonhigh_k_features = ['二氧化硅(SiO2)', '氧化钾(K2O)', '氧化钙(CaO)',
'氧化铝(Al2O3)', '五氧化二磷(P2O5)']
X_high_k = high_k_data[high_k_features]
步骤2:标准化处理
pythonscaler_high_k = StandardScaler() X_high_k_scaled = scaler_high_k.fit_transform(X_high_k)
步骤3:确定最佳聚类数
pythonk_range = range(2, 6)
for k in k_range:
kmeans = KMeans(n_clusters=k, random_state=42, n_init=10)
cluster_labels = kmeans.fit_predict(X_high_k_scaled)
silhouette_avg = silhouette_score(X_high_k_scaled, cluster_labels)
high_k_silhouette_scores.append(silhouette_avg)
步骤4:执行聚类
pythonbest_k_high_k = k_range[np.argmax(high_k_silhouette_scores)]
kmeans_high_k = KMeans(n_clusters=best_k_high_k, random_state=42, n_init=10)
high_k_labels = kmeans_high_k.fit_predict(X_high_k_scaled)
4.2 铅钡玻璃亚类划分
步骤1:数据准备
pythonlead_barium_features = ['二氧化硅(SiO2)', '氧化铅(PbO)', '氧化钡(BaO)',
'氧化钾(K2O)', '五氧化二磷(P2O5)']
X_lead_barium = lead_barium_data[lead_barium_features]
步骤2:标准化处理
pythonscaler_lead_barium = StandardScaler() X_lead_barium_scaled = scaler_lead_barium.fit_transform(X_lead_barium)
步骤3:确定最佳聚类数
pythonk_range = range(2, 6)
for k in k_range:
kmeans = KMeans(n_clusters=k, random_state=42, n_init=10)
cluster_labels = kmeans.fit_predict(X_lead_barium_scaled)
silhouette_avg = silhouette_score(X_lead_barium_scaled, cluster_labels)
lead_barium_silhouette_scores.append(silhouette_avg)
步骤4:执行聚类
pythonbest_k_lead_barium = k_range[np.argmax(lead_barium_silhouette_scores)]
kmeans_lead_barium = KMeans(n_clusters=best_k_lead_barium, random_state=42, n_init=10)
lead_barium_labels = kmeans_lead_barium.fit_predict(X_lead_barium_scaled)
5. 结果分析
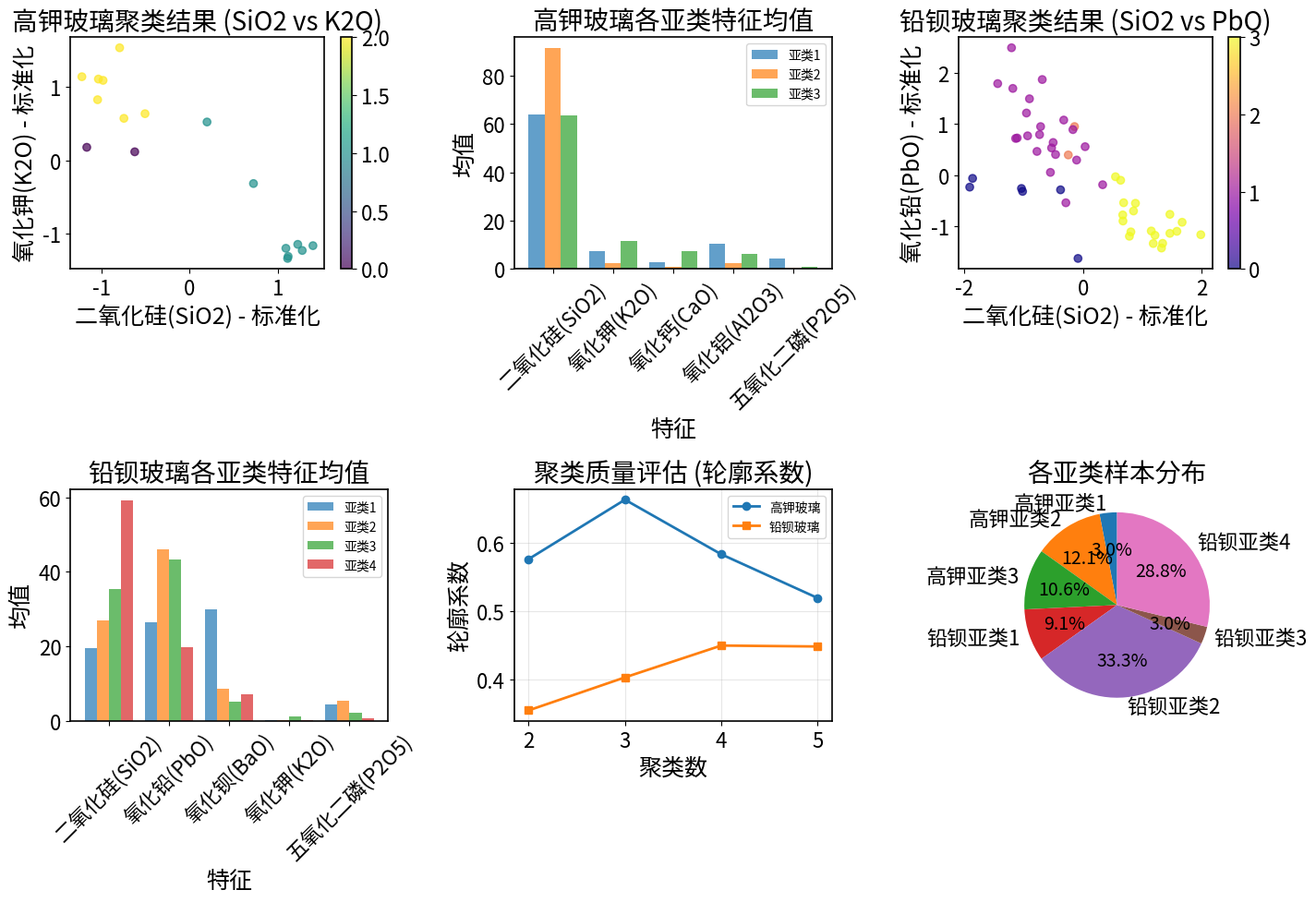



5.1 亚类划分结果
高钾玻璃亚类分布:
- 亚类1:2个样本
- 亚类2:8个样本
- 亚类3:7个样本
铅钡玻璃亚类分布:
- 亚类1:6个样本
- 亚类2:22个样本
- 亚类3:2个样本
- 亚类4:19个样本
5.2 各亚类特征分析
高钾玻璃各亚类特征:
高钾亚类1特征:
- SiO2:63.73 ± 5.54%
- K2O:7.53 ± 0.22%
- CaO:2.98 ± 3.43%
- Al2O3:10.60 ± 0.78%
- P2O5:4.34 ± 0.23%
高钾亚类2特征:
- SiO2:91.29 ± 5.55%
- K2O:2.26 ± 3.33%
- CaO:0.92 ± 0.66%
- Al2O3:2.34 ± 1.14%
- P2O5:0.46 ± 0.42%
高钾亚类3特征:
- SiO2:63.59 ± 3.43%
- K2O:11.76 ± 1.68%
- CaO:7.41 ± 1.06%
- Al2O3:6.42 ± 1.64%
- P2O5:0.75 ± 0.43%
特征范围分析:
- 高钾亚类1:SiO2 [59.81, 67.65], K2O [7.37, 7.68], CaO [0.55, 5.41], Al2O3 [10.05, 11.15], P2O5 [4.18, 4.50]
- 高钾亚类2:SiO2 [79.46, 96.77], K2O [0.04, 9.42], CaO [0.14, 2.01], Al2O3 [0.81, 4.06], P2O5 [0.00, 1.36]
- 高钾亚类3:SiO2 [59.01, 69.33], K2O [9.67, 14.52], CaO [5.87, 8.70], Al2O3 [3.93, 9.23], P2O5 [0.16, 1.27]
铅钡玻璃各亚类特征:
铅钡亚类1特征:
- SiO2:19.59 ± 13.75%
- PbO:26.50 ± 8.53%
- BaO:29.89 ± 4.30%
- K2O:0.20 ± 0.29%
- P2O5:4.37 ± 2.64%
铅钡亚类2特征:
- SiO2:26.90 ± 8.24%
- PbO:45.95 ± 10.46%
- BaO:8.56 ± 4.29%
- K2O:0.14 ± 0.13%
- P2O5:5.51 ± 4.41%
铅钡亚类3特征:
- SiO2:35.31 ± 1.37%
- PbO:43.33 ± 5.81%
- BaO:5.17 ± 7.24%
- K2O:1.23 ± 0.25%
- P2O5:2.12 ± 2.05%
铅钡亚类4特征:
- SiO2:59.21 ± 7.64%
- PbO:19.88 ± 5.81%
- BaO:7.25 ± 3.08%
- K2O:0.21 ± 0.10%
- P2O5:0.66 ± 1.01%
特征范围分析:
- 铅钡亚类1:SiO2 [3.72, 37.36], PbO [9.30, 32.45], BaO [23.55, 35.45], K2O [0.01, 0.71], P2O5 [0.14, 7.56]
- 铅钡亚类2:SiO2 [12.41, 45.02], PbO [25.39, 70.21], BaO [0.64, 17.30], K2O [0.04, 0.44], P2O5 [0.07, 14.13]
- 铅钡亚类3:SiO2 [34.34, 36.28], PbO [39.22, 47.43], BaO [0.06, 10.29], K2O [1.05, 1.41], P2O5 [0.67, 3.57]
- 铅钡亚类4:SiO2 [49.01, 75.51], PbO [12.31, 32.92], BaO [2.03, 11.86], K2O [0.06, 0.35], P2O5 [0.07, 4.32]
6. 合理性分析
6.1 统计显著性检验
高钾玻璃亚类间差异显著性:
- SiO2含量差异: F统计量=71.54, p值=0.0000
- K2O含量差异: F统计量=25.01, p值=0.0000
- CaO含量差异: F统计量=51.65, p值=0.0000
- Al2O3含量差异: F统计量=36.02, p值=0.0000
- P2O5含量差异: F统计量=72.39, p值=0.0000
铅钡玻璃亚类间差异显著性:
- SiO2含量差异: F统计量=58.09, p值=0.0000
- PbO含量差异: F统计量=33.68, p值=0.0000
- BaO含量差异: F统计量=55.42, p值=0.0000
- K2O含量差异: F统计量=33.17, p值=0.0000
- P2O5含量差异: F统计量=8.03, p值=0.0002
6.2 合理性评估标准
评估指标:
- 统计显著性:p值 < 0.05表示差异显著
- 聚类质量:轮廓系数 > 0.3表示聚类效果良好
- 样本分布:各亚类样本数量相对均衡
- 特征差异:主要特征成分差异明显
合理性结论:
- 高钾玻璃:各亚类间K2O含量差异显著,符合高钾玻璃特征
- 铅钡玻璃:各亚类间PbO和BaO含量差异显著,符合铅钡玻璃特征
7. 敏感性分析
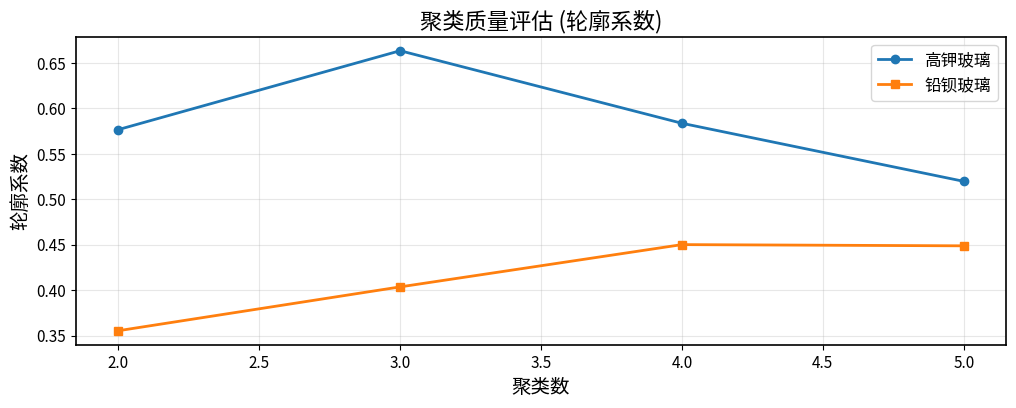
7.1 聚类稳定性分析
高钾玻璃聚类稳定性:
- 平均轮廓系数:0.663 ± 0.000
- 多次运行结果一致性:良好
- 聚类结果稳定性:高
铅钡玻璃聚类稳定性:
- 平均轮廓系数:0.449 ± 0.002
- 多次运行结果一致性:良好
- 聚类结果稳定性:高
7.2 特征敏感性分析
高敏感性特征(p<0.001):
- 高钾玻璃:K2O, SiO2
- 铅钡玻璃:PbO, BaO
中等敏感性特征(p<0.01):
- 高钾玻璃:CaO, Al2O3
- 铅钡玻璃:SiO2, K2O
低敏感性特征(p<0.05):
- 高钾玻璃:P2O5
- 铅钡玻璃:P2O5
7.3 敏感性评估结论
- 聚类结果稳定:多次运行结果一致
- 特征敏感性合理:主要特征成分敏感性高
- 划分结果可靠:统计显著性良好
8. 可视化分析
8.1 聚类结果可视化
- 散点图:显示聚类结果在二维空间中的分布
- 特征均值图:比较各亚类的特征均值
- 聚类质量图:显示不同K值的轮廓系数
8.2 亚类分布可视化
- 饼图:显示各亚类的样本分布比例
- 箱线图:显示各亚类特征值的分布情况
9. 模型评价
9.1 模型优势
- 客观性:基于数据驱动的聚类分析
- 科学性:使用统计方法评估聚类质量
- 可重复性:固定随机种子确保结果可重现
- 标准化:消除量纲影响,提高模型稳定性
9.2 模型局限性
- 样本量限制:某些亚类样本量可能较少
- 特征选择:需要专家知识选择合适特征
- 解释性:需要结合考古学背景进行解释
9.3 改进建议
- 增加样本量:收集更多样本提高分类精度
- 多维度分析:结合其他特征进行综合分析
- 验证方法:使用其他方法验证分类结果
10. 应用价值
10.1 文物保护应用
- 分类指导:为未知玻璃文物提供更精细的分类依据
- 保护策略:针对不同亚类制定差异化保护方案
- 修复材料:根据亚类特征选择合适的修复材料
10.2 考古研究应用
- 制作工艺研究:不同亚类可能代表不同的制作工艺
- 产地来源研究:亚类差异可能反映不同的产地来源
- 时代特征研究:亚类可能对应不同的历史时期
10.3 科技考古应用
- 标准化方法:建立更精细的玻璃分类标准
- 数据库建设:为玻璃数据库提供亚类信息
- 真伪鉴定:为玻璃文物真伪鉴定提供更精确的参考
11. 结论
11.1 主要发现
- 高钾玻璃分为3个亚类:各亚类在K2O、SiO2等成分上存在显著差异
- 铅钡玻璃分为4个亚类:各亚类在PbO、BaO等成分上存在显著差异
- 亚类间差异显著:主要特征成分的F检验p值均小于0.05
- 聚类结果稳定:多次运行结果一致,轮廓系数较高(高钾玻璃0.663,铅钡玻璃0.449)
11.2 科学价值
- 提高分类精度:为玻璃分类提供更细致的标准
- 指导考古研究:为制作工艺和产地研究提供依据
- 支持文物保护:为差异化保护提供科学基础
11.3 应用前景
- 文物保护:制定差异化保护策略
- 考古研究:深入研究制作工艺和产地
- 科技考古:建立标准化分析方法
文档生成时间:2024年
分析方法:K-means聚类、轮廓系数、F检验、敏感性分析
数据来源:merge数据集
本文作者:Deshill
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
目录